| Dr.-Ing. LOTHAR SEVEKE und
Dr.-Ing. ULRICH KORDON Spracherkenner-Zusatzmodul
für U-880-Mikrorechner
Mitteilung aus dem VEB Robotron-Elektronik Dresden und der Sektion Informationstechnik der TU Dresden Der Einsatz von Spracherkennern als neue Komponente der Rechnerperipherie erleichtert die Mensch-Maschine-Kommunikation. Die in diesem Beitrag vorgestellte Baugruppe und das Programm für U-880-Mikrorechner realisieren mit minimalem Aufwand die Erkennung von 50 isoliert gesprochenen Wörtern in Echtzeit. Dabei ist die Erkennungssicherheit bei dem Sprecher am größten, der dem Erkenner den gewünschten Wortschatz in seiner individuellen Aussprache übermittelt hat. Mit der Anwendung der Mikrorechentechnik
in immer neuen Bereichen der Volkswirtschaft entsteht das Bedürfnis,
die Kommunikation mit informationsverarbeitenden Maschinen zu verbessern,
d. h., sie den Gewohnheiten der zwischenmenschlichen Kommunikation und
den neuen Einsatzbedingungen (Spezifik des Arbeitsplatzes, naive Nutzer)
bestmöglich anzupassen. Dies wird in Ergänzung der konventionellen
Tastaturen und alphanumerischen Anzeigen bisher vor allem durch grafische
Ein- bzw. Ausgabemöglichkeiten realisiert. Es gibt jedoch auch Bestrebungen,
die Lautsprache, das natürliche Kommunikationsmittel des Menschen,
für den Informationsaustausch zu nutzen. Dazu werden sprachliche Äußerungen
des Nutzers (Wörter oder kurze Wortfolgen) in Steuerinformationen
für den Rechner umgewandelt bzw. werden Informationen des Rechners
an den Nutzer in Lautsprache umgesetzt.
Funktionsweise des Worterkenners Der im VEB Kombinat Robotron in Kooperation
mit der Technischen Universität Dresden entwickelte Spracherkennerzusatz
kann bis zu 50 verschiedene, isoliert gesprochene Wörter erkennen.
Der Wortschatz wird durch mehrmaliges Vorsprechen (fünf- bis achtmal)
im Lernprozeß vom Anwender selbst festgelegt, wobei gleichzeitig
die Ausspracheeigenheiten des jeweiligen Sprechers und die Geräuschumgebung
gespeichert werden. Zwischen zwei zu erkennenden Wörtern muß
eine Pause-von mindestens 200ms eingehalten werden. Das Erkennungsergebnis
liegt 200ms nach dem jeweiligen Wortende in Form der im Lernvorgang vereinbarten
Klassennummer vor. Die maximale Dauer einer zu erkennenden sprachlichen
Äußerung beträgt 1,8 s.
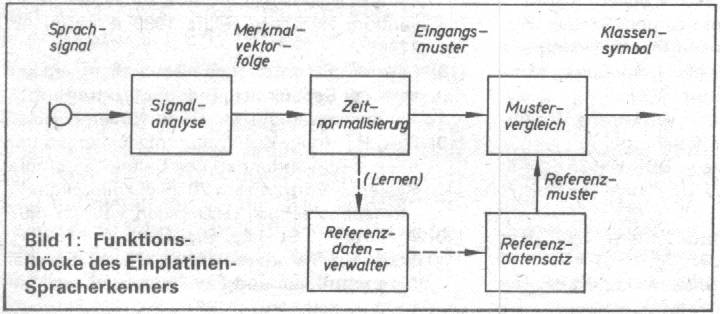
Bild 1: Funktionsblöcke des Einplatinen- Spracherkenners Signalanalyse Im Signalanalysator wird die vom Mikrofon
gelieferte Sprach-Zeit-Funktion in eine Folge von Merkmalvektoren umgewandelt,
die das Signal numerisch beschreiben. Dafür wurde ein Verfahren entwickelt,
das in Beachtung der Tatsache, daß absolut begrenzte Sprache noch
ausreichend verständlich ist, nur die Abstände zwischen benachbarten
Nulldurchgängen im Signal auswertet. Es stellt einen Kompromiß
zwischen Leistungsfähigkeit und Kosten dar, da einerseits alte Informationen
aus der Amplitudendynamik verlorengehen und die Informationen über
Oberwellenanteile gestört sind, andererseits diese Messung mit wenig
Aufwand realisierbar ist.
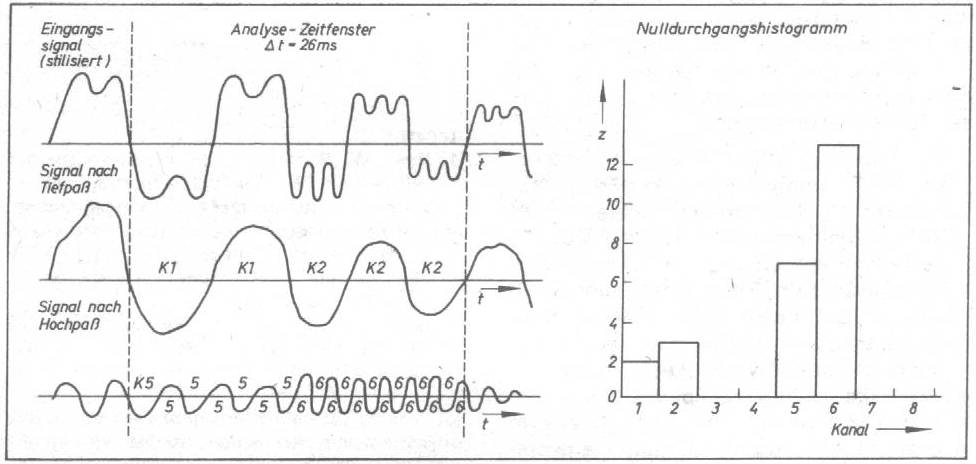
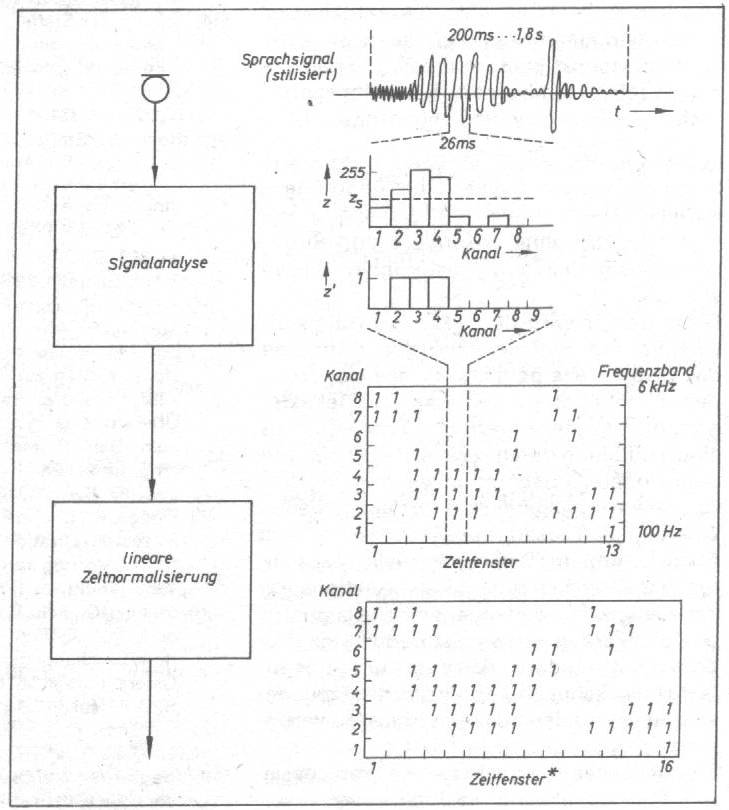
Bild 2: Bildung des Nulldurchgangshistogramms Die getrennte Weiterverarbeitung beider Frequenzbereiche soll die "Verdeckung" der hoch- durch die niederfrequenten Signalanteile und umgekehrt vermindern. Der Messung der Nulldurchgangsabstände geht eine Umwandlung der beiden gefilterten analogen Signale in Rechteckimpulse voraus. Die Flanken der beiden Pulse lösen über die CTC im angeschlossenen Mikrorechner lnterrupts aus, deren Abstände mit Hilfe eines CTC-Zählkanals bestimmt werden. Die möglichen Nulldurchgangsabstände in den beiden Frequenzbereichen werden in je vier Intervallklassen (im Bild 2 als Kanäle bezeichnet) eingeteilt, deren Grenzen in der Frequenzebene denen der Frequenzgruppen im Wahrnehmungsbereich des menschlichen Innenohres entsprechen. Das Analyseprogramm ermittelt die Häufigkeit der Repräsentanten jeder Intervallklasse in einem Zeitfenster von etwa 26ms und bestimmt so ein sogenanntes Nulldurchgangshistogramm z. Durch Vergleich mit einem festen Schwellwert z(s) wird jeder der acht Häufigkeitswerte im Nulldurchgangshistogramm in nur einem Bit abgebildet (s. Bild 3). Bild 3: Bestimmung der Wortmuster Für jede sprachliche Einheit entsteht
so eine Folge von 8-bit-Merkmalvektoren, wobei jeder Vektor einen Signalabschnitt
von 26 ms beschreibt und die Anzahl der Vektoren von der Sprechdauer abhängt.
Bild 4: Muster gesprochener Ziffern Lernen Das Anlernen des Spracherkenners durch
den Nutzer selbst dient dem Aufbau eines sprecherspezifischen Referenzdatensatzes,
in dem Muster aller geläufigen Aussprachevarianten der Wörter
des gewählten Wortschatzes enthalten sein sollten. Der Nutzer spricht
dazu die gewünschten Wörter in das Mikrofon und vergleicht das
bei der ausgeführten Kontrollerkennung ermittelte Ergebnis mit dem
von ihm beabsichtigten. Bei Nichtübereinstimmung ist eine entsprechende
Korrektureingabe über eine Tastatur erforderlich. Durch dieses Prinzip
bekommt der Sprecher schnell einen Eindruck von der Güte des aktuellen
Referenzmustersatzes und der Nichteignung bestimmter Wörter. Er kann
auch besonders schwierige Wörter häufiger anlernen. Treten keine
Verwechslungen oder Rückweisungen mehr auf, kann er den Lernvorgang
abbrechen. Je nach den phonetischen Abständen der gewählten Wörter
und der Stabilität der Artikulation wird der Lernprozeß nach
drei- bis achtmaligem Sprechen jedes vorkommenden Wortes beendet sein.
Erkennen Ist der Referenzmusterspeicher durch Lernen
oder das Einlesen eines Referenzdatensatzes auf den Sprecher eingestellt,
kann der Erkenner für die Spracheingabe eingesetzt werden. Der Erkennungsalgorithmus,
der schon beim Lernen für die Kontrollerkennung wirksam wurde, beruht
auf einem bitweisen Mustervergleich (Hammingdistanz) zwischen dem Muster
des eben gesprochenen Wortes und allen Mustern der Wörter aus dem
Referenzspeicher. Dabei wird das Referenzmuster mit der geringsten Distanz
zum Eingangsmuster gesucht. Unterschreitet diese minimale Distanz einen
vorgegebenen Schwellwert (Rückweisungsschwelle), wird die dem entsprechenden
Referenzmuster zugeordnete Klassennummer als Erkennungsergebnis in der
vereinbarten Speicherzelle abgelegt, andernfalls erfolgt eine Rückweisung.
Das Wort ist dann noch einmal zu sprechen. Der Erkennungsalgorithmus wird
von der Wortsignaldetektion aktiviert, die interruptgesteuert im Hintergrund
arbeitet und das Vorhandensein von Sprachsignalen im Eingangssignal meldet.
Er beginnt sofort bei Beginn einer Pause am sogenannten prognostizierten
Wortende mit dem Vergleich der Muster. Erst nach dem Ablauf von 200 ms,
die zur sicheren Erkennung des Wortendes notwendig sind, wird das Erkennungsergebnis
freigegeben. Sollte sich die
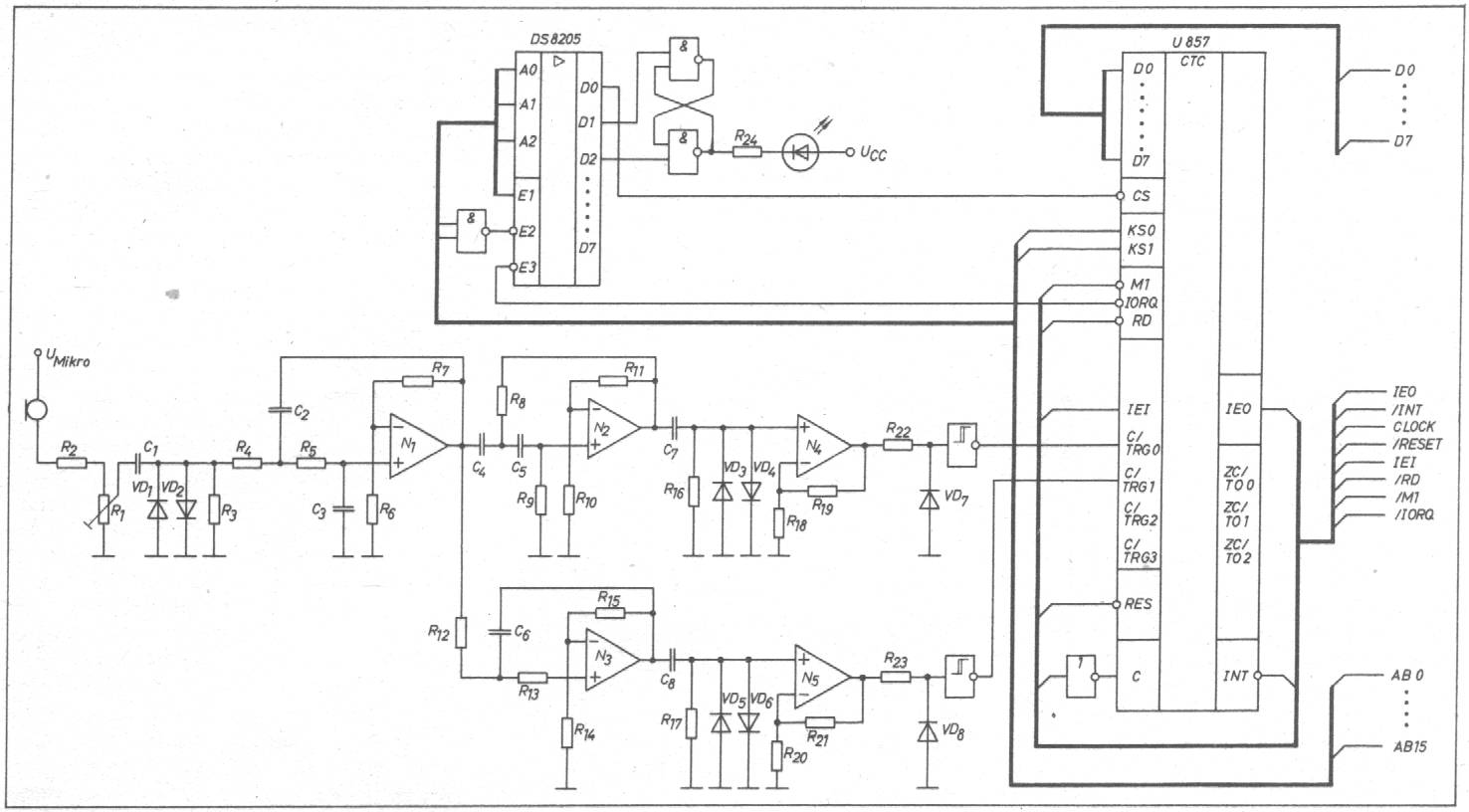
Schaltungstechnische Realisierung Die für den Spracherkenner erforderliche Zusatzschaltung hat folgende Aufgaben zu erfüllen: Anpassung des Signalwandlers
Das daraus resultierende Schaltbild zeigt Bild 5. Bild 5: Schaltung des Zusatzmoduls (E3 und IORQ nicht miteinander verbunden, beide im Steuerbus) Eingangsverstärker Der Eingangsverstärker dient der Anpassung
des verwendeten Mikrofons. Er besitzt Tiefpaßverhalten, um den Sprachfrequenzbereich
auf den verarbeitbaren Bereich zu beschränken. Das hier verwendete
Mikrofon SP75 vom VEB Funkwerk Kölleda besitzt einen eigenen Vorverstärker,
so daß der Eingangsverstärker nur aus dem aktiven Tiefpaß
besteht, der ab 7kHz einen Abfall von 12 dB/Oktave aufweist. Die Verstärkung
des mit N(1) realisierten Tiefpasses zweiten Grades beträgt 40 dB.
Die Resonanzüberhöhung verwirklicht eine leichte Preemphasis,
die den Leistungsabfall des Sprachsignals bei hohen Frequenzen mindern
soll.
Kanaltrennung Die Aufteilung in die beiden Frequenzkanäle
nehmen die durch N(2) und N(3) gebildeten Hoch- bzw. Tiefpässe zweiten
Grades vor. Zur Gewährleistung der Stabilität wurde eine Verstärkung
von v = 5 festgelegt. Die Trennfrequenz liegt bei 1 kHz, da dadurch die
für das Sprachsignal charakteristischen Frequenzen des ersten und
zweiten spektralen Maximums in getrennten Kanälen abgebildet werden.
Die verwendeten Schaltungen der Filter zeichnen sich durch minimalen Bauelementeaufwand
und Unempfindlichkeit gegen Toleranzen der frequenzbestimmenden Bauelemente
aus. Zur Dimensionierung wurden die in [1] angegebenen Anwendungskriterien
und Entwurfsbedingungen verwendet.
Amplitudenbegrenzung Die Bildung der für eine digitale
Auswertung erforderlichen amplitudenbegrenzten Signale erfolgt mit den
Triggerstufen N(4) und N(5). VD(3) bis VD(6) dienen der Pegelbegrenzung.
Da die verwendeten Operationsverstärker mit interner Frequenzkompensation
eine zu geringe Spannungsanstiegsgeschwindigkeit aufwiesen, wurden zur
Versteilerung der Flanken TTL-Schmitt-Trigger nachgeschaltet.
Digitalteil Der Digitalteil unterstützt einerseits
die Bildung der Nulldurchgangshistogrammfolgen, andererseits realisiert
er die Ankopplung des Spracheingabemoduls an den Bus des verwendeten U-880-Mikrorechners.
Grundelement des Digitaltells ist die ZählerZeitgeber-IS U 857 D (CTC).
Die Kanäle 0 und 1 empfangen die Flanken der Eingangssignale für
die Messung der Nulldurchgangsabstände. Kanal 2 dient als Zeitgeber
für die Dauer der Analysezeitfenster. Über die Bussignale der
CTC ist ein problemloser Anschluß an den steuernden Rechner möglich.
Hier sind Treiber einzuschalten, die im Bild 5 nicht gezeigt sind. Der
Spracheingabemodul belegt sechs E-A-Adressen. Neben den vier für die
CTC sind noch zwei für das Ein- bzw. Ausschalten einer Sprechaufforderungsanzeige
mit VD(9) erforderlich, die über ein RS-Flip-Flop angesteuert wird.
Die verwendeten Adressen sind mit Rücksicht auf einen minimalen Bauelementeaufwand
nicht wählbar.
Abgleich der Baugruppe Der EingangspegelsteHer R(1) ist so einzustellen,
daß die Hoch- bzw. Tiefpaßstufe auch bei Pegelspitzen mit unbegrenztem
Signal angesteuert werden. Die Einstellung der Triggerschwellen von N(4)
und N(5) erfolgt unterschiedlich. Um beide Kanäle gleich auszusteuern,
haben sich im Hochpaßkanal eine Schwelle von -28dB bei 2kHz und im
Tiefpaßkanal von -18dB bei 50OHz gegenüber Vollaussteuerung
als optimal erwiesen. Im praktischen Einsatz ist eine Anpassung der Einstellung
von R(1) an das Umgebungsgeräusch empfehlenswert.
Programm und Rechnereinbindung Programmstruktur Das Programm für den Betrieb des Spracherkenners umfaßt ein Hauptprogramm für das Anlernen mit je einem Eingang für das Neulernen (leerer Referenzspeicher) und das Weiterlernen (aufbauend auf schon vorhandenem Referenzwissen) und ein Unterprogramm für die Erkennung eines Signalabschnittes. Es ist als Assemblerquellprogramm verfügbar. Das zugehörige Maschinenprogramm mit einem Speicherbedarf von 2 Kbyte ist PROM-fähig und kann auf beliebige 1-Kbyte-Grenzen im Speicherraum des Wirtsrechners geladen werden. Es wird ein Arbeitsspeicher von 4 Kbyte benötigt, der an beliebigen 1-Kbyte-Grenzen beginnen kann. Das Programm gliedert sich in drei wesentliche funktionelle Segmente: Anpassung an Wirtsrechner
Die ersten beiden Segmente können
durch den Nutzer modifiziert werden.
Programmschnittstellen Die Eingänge des Hauptprogramms LERNEN werden über folgende Adressen aufgerufen (mit JMP): NEULERN: Lernen mit anfangs leerem Referenzspeicher
Nach Abschluß des Lernprogramms erfolgt
ein Sprung zu einer vereinbarten Adresse (z. B. Warmstart des Betriebssystems).
In den 4Kbyte des Arbeitsspeichers liegt ein Referenzdatensatz vor, der
auf ein peripheres Medium ausgelagert werden bzw. als Basis für Abarbeitung
des Unterprogramms RECOG (Erkennung eines Signalabschnittes) dienen kann.
Einbindung in den Wirtsrechner Die unmittelbare Anpassung des Spracherkennerprogramms
an die Umgebung im Wirtsrechner erfolgt durch Modifikation des Assemblerquellprogramms
an deutlich gekennzeichneten Stellen. Es sind z. B. folgende Speicheradressen
anzugeben:
Drei aufeinanderfolgende Adressen im E-A-Adreßraum
sind zu suchen:
Folgende Kommunikationsunterprogramme sind
mit Hilfe des Betriebssystems des Wirtsrechners zu realisieren:
Neben diesen programmtechnischen Anpassungen
können zwei interne Programmkonstanten durch den Nutzer experimentell
variiert werden, um eine optimale Anpassung des Erkenners an die Einsatzbedingungen
zu erreichen:
Neben dieser Anpassung an die Rechnerumgebung
sollte vor allem der Aufruf des Unterprogramms zur Erkennung eines Wortes
optimal in die vom Anwendungsfall abhängige Kommunikation eingebunden
werden, um die Effekte der Spracheingabe voll zu nutzen.
Besonderheiten der Bedienung Beide Lernprogramme zeigen nach dem Start
die Anzahl der im Arbeitsspeicher abgelegten Referenzmuster an (max. 200).
Dem Nutzer wird damit eine Information über weitere Möglichkeiten
zum Nachlernen gegeben. Durch einen Abbruch des Lernvorgangs und einen
folgenden Aufruf von WEILERN ist eine ständige Kontrolle des Füllstandes
des Referenzspeichers möglich.
Einsatzergebnisse Der Spracherkenner-Zusatzmodul wurde als
billige, nachnutzbare Variante des Einplatinen-Spracherkenners ESE K 7824
von VEB Robotron Elektronik Dresden entwickelt. Mit einem international
üblichen Test nach [2] wurde eine Erkennungsquote von 97% erreicht.
Den ESE K 7824 erprobten Anwender in verschiedenen Bereichen der Volkswirtschaft.
Die Erprobungsergebnisse sind in [3] ausführlich dargestellt.
Literatur
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}